

Сервис привлекает низкой стоимостью, но заставляет танцевать с бубном, если задачи проекта выходят за рамки преднастроенных в нём шаблонов. Дело в специфическом формате ответов на запросы.
Плюсы и странности Yandex Vision
Пользоваться сервисом действительно дёшево: распознавание тысячи документов будет стоить всего 100 рублей. Есть преднастроенные шаблоны. Например, система безошибочно считывает паспорта и водительские удостоверения. Шаблон для паспорта мы встроили в форму регистрации пользователей на одной из разработанных платформ.

Работает сервис и с изображениями: распознает лица, умеет классифицировать контент (соответствие нужному качеству, наличие взрослого контента), может отследить вотермарку на изображении.
С другой стороны, пословное распознавание с указанием точности будет кстати, когда нужно из большого документа фиксировать только определённые значения. Так у нас было на «Цессионарии», но о нём позже. Можно задавать интервал корректности. Например, отображать в системе результат распознавания, только если его точность от 90 до 100 или не ниже определенного значения. Если результат хуже, проверять результат распознавания живым человеком. Такое бывает, например, если документ криво отсканирован.
На момент написания этого текста Yandex Vision работает с ограничениями. Среди прочего это касается распознавания языков. Сервис различает начертания, но в результате распознавания текста выводит только один язык, преимущественно встречающийся в документе. Это неудобно, если нужно распознать мультиязычный текст.
Бывает, что русское слово система может распознать как частично английское, если в нём есть буквы, которые пишутся идентично в обоих языках. Такое распознавание приходится корректировать вручную.
Результаты обнаружения лиц в Yandex Vision, на наш взгляд, избыточны, опять же, на уровне кода. Лица людей на картинке сервис выделяет прямоугольниками и в ответе на запрос возвращает их координаты.

Обычно при известных координатах всего двух углов выделения, остальные два угла прямоугольника легко найти. Yandex Vision прописывает все четыре, как будто подразумевается, что поле распознавания может быть не прямоугольником, а какой-то более сложной четырехугольной фигурой. Пока непонятно, может ли такое быть и зачем такая избыточность информации в координатах.
Для чего мы использовали сервис
Yandex Vision пригодился нам в двух продуктах. В одном с его помощью настроили распознавание паспортных данных для регистрации на платформе. Это тривиальная задача, с которой сервис на 100% справляется.
Сложную интеграцию с Yandex Vision мы реализовали для системы «Цессионарий». Она автоматизирует работу департамента судебного взыскания долгов. Распознавать предстояло сканы судебных приказов, чтобы минимизировать ручной труд и повысить степень автоматизации процессов в компании. Бизнесу дешевле оплачивать сервис, чем платить за ту же работу специалистам.
Для таких нетривиальных задач стоит оценить и возможности создания специализированного ML под процессы компании. Однако, Yandex Vision тоже можно подстроить под запрос, дополнив его функциональность кастомной логикой.
Опыт сложной интеграции: задачи, объём работ и результаты
Главной задачей было избавить сотрудников компании клиента от ручного труда в ходе работы с судебными документами. Обрабатывать их нужно было в больших количествах, поэтому и автоматическое распознавание настроили так, чтобы загружать документы можно было «пачками».
Сначала для теста мы взяли API Yandex Vision без подключения к основной системе. Специалисты загружали архив отсканированных документов, а в ответ получали Excel-таблицу. В ней отображались распознанные данные для каждого файла из архива: ФИО, дата, номер кредитного договора, сумма задолженности и т.д. Так, в течение пары месяцев проверяли работоспособность технологии, а затем внедрили Yandex Vision непосредственно в «Цессионарий».
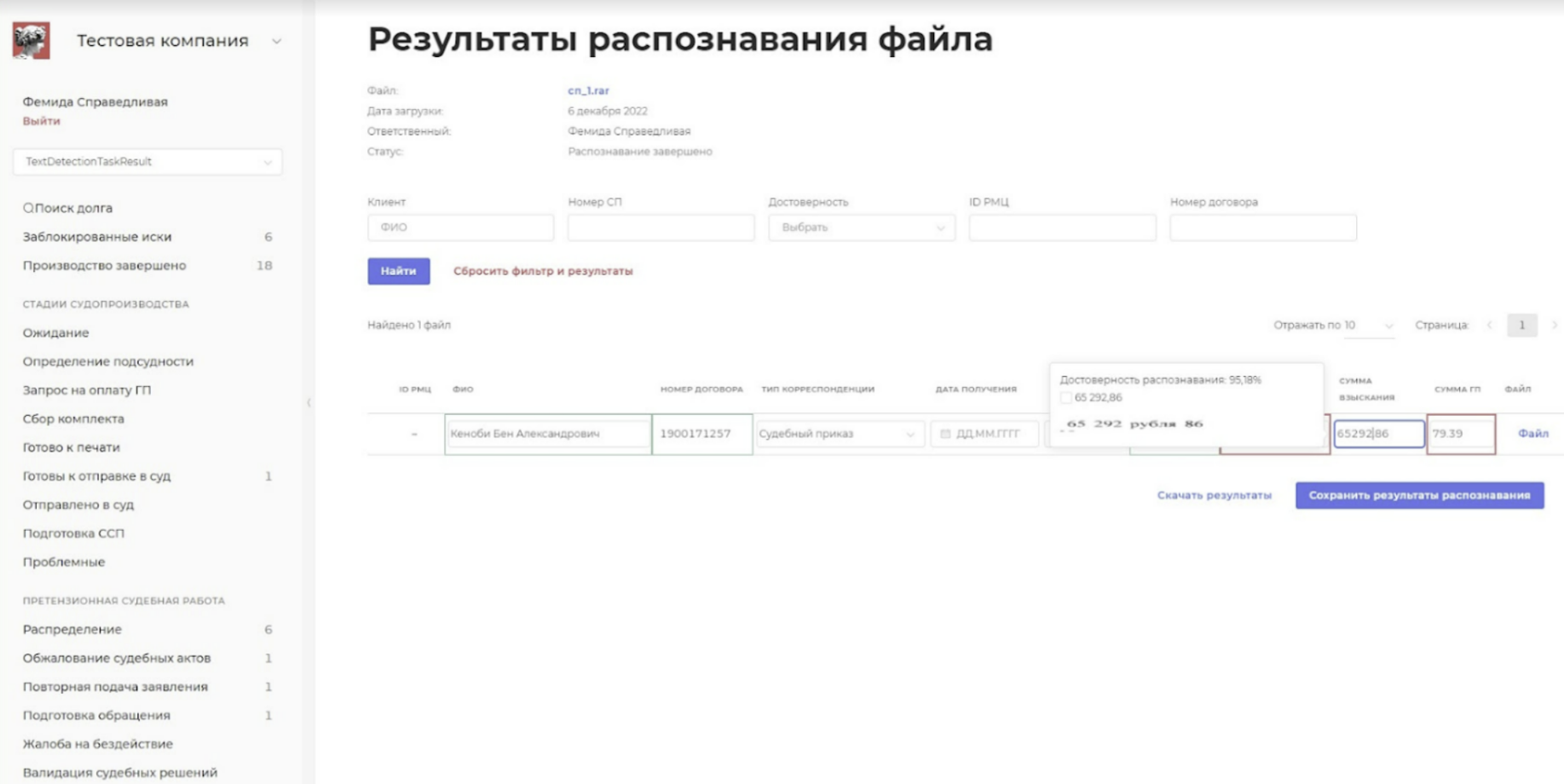
Сложность этой интеграции была в нешаблонности распознаваемых документов. Нет единого стандарта для составления судебных приказов, поэтому в каждом суде их могут оформлять по-своему. Чтобы Yandex Vision корректно считывал нужные данные, мы разработали дополнительную логику работы сервиса.
Методом пристального взгляда выцепляли в документах нужные слова, за которыми следовали искомые данные, изменяющиеся от документа к документу. Например, после слов «взыскать с» должно идти ФИО, которое нам нужно. Или «задолженность по договору займа №», и дальше идет номер, который будет зафиксирован. Такие паттерны встроили в логику распознавания на уровне кода, загрузили тестовую пачку документов и смотрели, что не распозналось. Повторяли вышеописанные действия, пока не вывели схемы для распознавания подавляющего большинства документов.
На запуске мы добились корректного распознавания 80% всех документов. Остальные 20% – документы, составленные грубо говоря «своими словами», опять же из-за отсутствия шаблона.
Многие фичи Yandex Vision до сих пор находятся в стадии Preview, о чем свидетельствуют соответствующие пояснения в документации. Однако это не мешает эффективно использовать сервис для решения задач, даже если они нестандартные. Теперь мы знаем, как это работает и с радостью поможем сделать интеграцию для вашего бизнеса! 🙂
Автор: Сергей Васнин
Запись и редактура: Анастасия Мартынова



















